作业目标
能够正确解析和执行单条指令
具体要求
实现以下opcode对应的指令的解析和执行:
- opcode=0x05 ADD eAX,Iv
- opcode=0x0D OR eAX,Iv
- opcode=0x15 ADC eAX,Iv
- opcode=0x1D SBB eAX,Iv
- opcode=0x25 AND eAX,Iv
- opcode=0x2D SUB eAX,Iv
- opcode=0x35 XOR eAX,Iv
- opcode=0x3D CMP eAX,Iv
- opcode=0x58 POP eAX
- opcode=0x59 POP eCX
- opcode=0x5a POP eDX
- opcode=0x53 PUSH eBX
- opcode=0x74 JZ Jb
- opcode=0xb8 MOV eAX,Iv
编写汇编指令
机器如何运行程序?
程序装载入内存之后 , 就是由一条又一条称为指令的 01 串所构成的序列。 CPU 能够解读这些由 01 串编码好的指令并将其转换成对应的操作,这时候留给CPU的任务就是不断地进行指令的读取、译码、执行。
现在需要实现的目的, 就是能够先把程序装载到内存中去, 并且让CPU进行指令读取
注:所有指令执行均需要按照 intel i386规范,具体参见如下。此文档已经被放在代码根目录下。
https://css.csail.mit.edu/6.858/2014/readings/i386.pdf
指令结构
一条指令主要包含如下两部分内容
- 指令操作码 (opcode) , 指明了这一条指令的行为
- 指令操作数 (operand) , 对于涉及到数据的指令, 我们需要给出操作对象. 操作数来源可以是立即数(immediate) , 寄存器编号 (register) , 或者是一个内存地址 (mem_addr)
IA-32体系结构中 , 指令结构如下
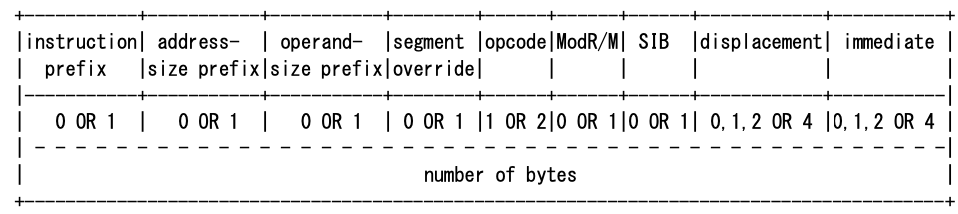
- 前缀(prefix),考虑到作业难度,本次作业不使用前缀,也就是所有指令都从opcode开始。4种前缀和opcode的值域均是相互之间独立的,这样计算机才能够正确对指令进行解析。前缀包含了一部分指令信息,比如操作码前缀(oprand-size prefix)如果是0x66,则操作数长度为16位,该前缀如果为空则操作数长度是默认的32位
- ModR/M , SIB , displacement 码 , 这三个域通过组合方式, 来决定最终的操作数寻址方式
- immediate 为指令可能用到的立即数
CPU执行指令分为如下几步
- 根据当前cs段寄存器中的段选择符和 eip*寄存器的值, 组合成48-bits的逻辑地址访问内存,取指令 *instr
- 译码。根据 instr 中的 opcode 查表获取指令类型和长度,并且根据需要解析 ModR/M , SIB , displacement 码。此时已经知晓的信息是{ 操作类型,操作数寻址方式,地址(如果有),立即数(如果有),该条指令长度}
- 根据指令译码结果 , 进行相应的指令执行。执行完毕之后根据指令长度,更新 eip , 如果还有接下来的一条指令,就返回到1步骤, 否则运行结束
友情提示:如果发生指令跳转,跳转指令返回的长度应该是0
框架代码执行流
- 由于本次作业只要求能够对单条指令进行译码,测试用例会将一条指令写入磁盘起始处,并初始化eip的值为0,并在内存中初始化段表,为这个只有一条指令的程序分配一个段
- CPU循环读取1个字节,直到发现某个字节为opcode
- InstrFactory根据opcode查询instr.all_instrs.Opcode.java中的表格,构建对应的指令类(需要自己在all_instrs包下创建,实现Instruction接口,类名首字母大写,其余字母小写)
- CPU调用指令类的exec接口,指令类根据自身的opcode确定指令长度(注意同一条指令可能对应多个opcode,指令长度和字段含义也有所不同),调用mmu.read读取指令的剩余部分并执行
- 指令类执行完毕需要返回执行的指令长度(字节)
注意事项
- CPU.execInstr(number)是测试用例使用到的接口,要求连续执行number条指令。本次作业中number恒定为1
- CPU.execInstr()会从eip寄存器中读取下一条指令的地址,传给CPU.decodeAndExecute(eip)
- CPU.decodeAndExecute(eip)会从内存中取出下一条可执行的指令的opcode,创建对应的指令类并要求执行
- CPU_State维护了一个所有寄存器的列表,注意段寄存器只有16位,其他寄存器都是32位的
- 由于esp是向低地址压栈,我们在Memory中增加了一个HashMap用于模拟栈结构,并提供了对应的接口,push和pop可能会使用到。当然你们也可以用自己更喜欢的数据结构替换这个简陋的栈。
完整opcode在https://github.com/CaribouW/pa2018/blob/master/nemu/src/cpu/instr/decode/opcode.c
或者参考目录下的”英特尔80386程序员参考手册(i386)intel.pdf”的414页的单字节opcode表
或者参考目录下opcode.jpg
1 | typedef int (*instr_func)(uint32_t eip, uint8_t opcode); |
参考代码和资料
- 计科PA2019大作业文档中关于指令集部分的说明
https://nju-projectn.github.io/ics-pa-gitbook/ics2019/i386-intro.html - 关于如何理解opcode表格各字段含义
https://css.csail.mit.edu/6.858/2014/readings/i386/appa.htm
这里也可以直接阅读”英特尔80386程序员参考手册(i386)intel.pdf” - 我们提供了一份完整基于c的参考代码,但是具体实现和代码架构有所不同
https://github.com/CaribouW/pa2018/tree/master
这里举一个指令实现的例子
1 | make_instr_func(imul_rm2r_v) |
imul_rm2_r_v 这里是通过一个宏替换(make_instr_func)形成函数指针 + opcode_entry表驱动的, 执行的行为是 有符号整数乘法, 操作数分别是一个内存取值和一个寄存器取值, 乘法结果放回到寄存器中
我们通过 modrm_r_rm(eip + 1, &r, &rm); 做了两件事
- 获取整个指令的长度并且返回
- 将操作数的地址放到
r , rm中
然后我们进行操作数的值的读取
1 | operand_read(&r); |
并且利用之前实现好的 alu_imul 来进行计算. 并且通过 operand_write 进行结果写回,最终返回整个指令的长度, 便于读取下一条指令的信息
所有的指令都已经实现在了 https://github.com/CaribouW/pa2018/tree/master/nemu/src/cpu/instr 下,不知道怎么实现的同学可以参考以上代码